

Multiple clients often need to read and update the same data simultaneously. Without a proper concurrency model, data can become inconsistent, transactions may interfere with each other, and systems risk losing reliability. SQL Server addresses this challenge through concurrency control and locking mechanisms.
For beginners, understanding concurrency may feel abstract, but it is fundamental to designing robust database systems. For enterprises, concurrency is a critical performance factor: poor configuration can lead to deadlocks, blocking, and user dissatisfaction. This article provides a deep dive into SQL Server concurrency and locking, explaining the concepts, mechanisms, and best practices for managing them effectively.
The Concept of Concurrency
Concurrency is the ability of a database system to handle multiple operations simultaneously. SQL Server achieves this by managing how data is accessed and updated by multiple users at the same time.
Concurrency must strike a balance between two goals:
- Data Integrity – Ensuring that transactions do not produce inconsistent or corrupt data.
- System Performance – Maximizing throughput without excessive blocking.
SQL Server offers two main models: pessimistic and optimistic concurrency.
Pessimistic Concurrency
In pessimistic concurrency, SQL Server assumes that conflicts are likely to occur. Therefore, it locks resources when they are accessed to prevent other users from making conflicting changes.
- Shared Locks – Allow multiple users to read a resource simultaneously but block writes.
- Exclusive Locks – Prevent any other access (read or write) while a transaction is updating a resource.
- Update Locks – Used to avoid deadlocks when promoting from a shared lock to an exclusive lock.
Pessimistic concurrency is effective in environments with high contention where multiple users frequently attempt to modify the same data.
Optimistic Concurrency
Optimistic concurrency assumes conflicts are rare. Instead of locking rows, SQL Server allows multiple users to read and attempt to update data simultaneously. When a conflict occurs (e.g., two users updating the same row), the system resolves it by rejecting one transaction.
Optimistic concurrency is implemented using row versioning. Older versions of rows are stored in tempdb, enabling reads and writes without blocking.
This model is well-suited for systems with a high volume of reads and fewer writes, such as reporting or analytics workloads.
Isolation Levels in SQL Server
SQL Server provides multiple isolation levels that define how transactions interact.
- Read Uncommitted – Allows dirty reads; no shared locks are applied. Fast but risky.
- Read Committed (default) – Prevents dirty reads by placing shared locks during reads.
- Repeatable Read – Prevents dirty reads and non-repeatable reads by holding locks until the transaction completes.
- Serializable – Strictest isolation; prevents dirty reads, non-repeatable reads, and phantom reads.
- Snapshot – Implements optimistic concurrency using row versioning instead of locks.
Choosing the correct isolation level depends on workload requirements.
Deadlocks and Blocking
- Blocking occurs when one transaction holds a lock and another transaction must wait for it to be released. While blocking is normal, excessive blocking reduces performance.
- Deadlocks occur when two transactions hold locks and wait for each other to release resources, creating a cycle. SQL Server automatically detects and resolves deadlocks by terminating one transaction.
Managing Concurrency in Practice
1. Monitor Locks and Transactions
- Use
sys.dm_tran_locksandsys.dm_exec_requeststo analyze active locks. - SSMS Activity Monitor provides a GUI for detecting blocking and deadlocks.
2. Apply the Right Isolation Level
- For high read, low write workloads: use Snapshot.
- For financial systems requiring strong consistency: use Serializable.
- For general OLTP workloads: Read Committed is often sufficient.
3. Optimize Transactions
- Keep transactions short and precise. Long-running transactions increase lock duration.
- Access resources in a consistent order to reduce deadlock risk.
4. Use Lock Hints Carefully
SQL Server supports lock hints such as WITH (NOLOCK) or WITH (ROWLOCK). These override default behavior but should be used cautiously to avoid data integrity issues.
5. Indexing Strategy
Proper indexes reduce the number of rows locked during queries, improving concurrency.
Example: Demonstrating Locking
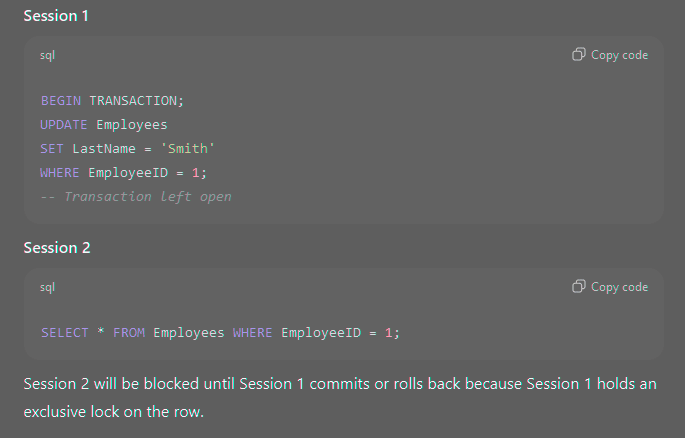
Session 2 will be blocked until Session 1 commits or rolls back because Session 1 holds an exclusive lock on the row.
Example: Using Snapshot Isolation
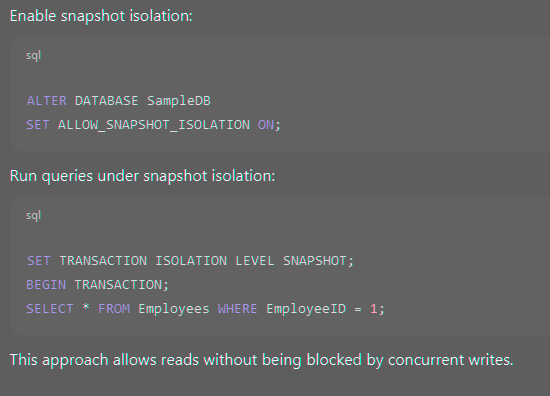
This approach allows reads without being blocked by concurrent writes.
Best Practices for Enterprises
- Understand Workloads – OLTP and OLAP systems have different concurrency requirements.
- Use Monitoring Tools – Leverage Extended Events, DMVs, and third-party tools to detect locking bottlenecks.
- Balance Isolation and Performance – Avoid overly strict isolation levels unless required.
- Educate Developers – Ensure application teams understand how transactions affect database concurrency.
- Regularly Review Queries – Poorly written queries often cause unnecessary locking and blocking.
Concurrency and locking are central to SQL Server’s ability to handle multi-user workloads reliably. By understanding pessimistic vs. optimistic concurrency, selecting appropriate isolation levels, and applying best practices, administrators and developers can design systems that maintain both consistency and performance.
SQL Server provides powerful tools for managing concurrency; the key is choosing the right balance between integrity and throughput based on workload requirements.







